ScanSnap Manager では設定の中で「検索可能な PDF」にするかしないかの選択肢があります。そこで実際に検索可能な PDF を作ってみた結果がどの程度の精度なのか気になったのでちょっと調べてみました。
自分は読み込んだ紙料を Evernote に読み込んでいるので、まずはそちらでどの程度なのかを試してみます。
検証に使った紙料はデルプラドから発売されていた世界のレーシングカーコレクションの中からランチアストラトスに付属していた冊子です。
「ストラトス」をキーワードに検索をしてみるとこんな感じ。

もちろん、他のページの「ストラトス」もハイライトされていますが、総数 31ヶ所のところ漏れは 9ヶ所。精度としては約 71%となりました。
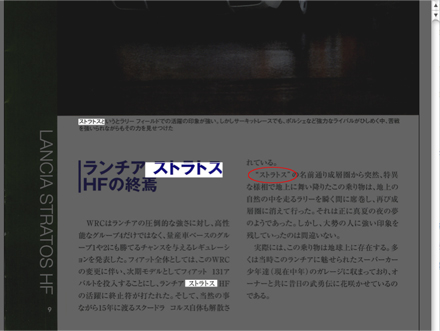
例えば ○で囲んだ「ストラトス」は認識してくれませんでした。
次に、PDF ファイルを Acrobat Reader を使って検索してみました。この場合の漏れは 6ヶ所。この時の精度は約 81%となります。また、標準アプリの「プレビュー」を使って同じことをすると漏れは 9ヶ所でした。Evernote と同じ割合ですね。
ということで、使うアプリによっても差が出ることが分かりました。おそらく文章の書き方やキーワードによっても変わってきそうですし、要因が ScanSnap Manager にあるのか、PDF ビューワーにあるのかがよく分からなくなってきましたが (^^;; もう少し検出率は上げて欲しいですね。
レビューありがとうございます。
膨大に資料があれば、使えるのかもしれないというレベルですね。
手で探すのが超不得意な人用かもですね。
OCRって昔からありますけど、需要が無いのかしらん。
劇的な進歩が無いですよね。
Scansnapを使えば、身の回りにある雑誌が全部デジタル化されるというのに・・・。
コメントありがとうございます。
そうだねぇ〜そんな感じかな。まぁ無いよりはマシってくらい?(^^;;
まぁしかし ScanSnap 自体はとってもナイスですよ。
で、やっぱり書籍を電子化する需要ってまだまだってことじゃないかな?
ちゃんとウォッチしてなかったから間違った認識なのかもしれないけど ScanSnap 以外のドキュメントスキャナが増えだしたのって最近じゃない?
市場としてはまだまだこれからなのかも… 電子書籍との相乗効果が出るようなら面白くなるかもね。